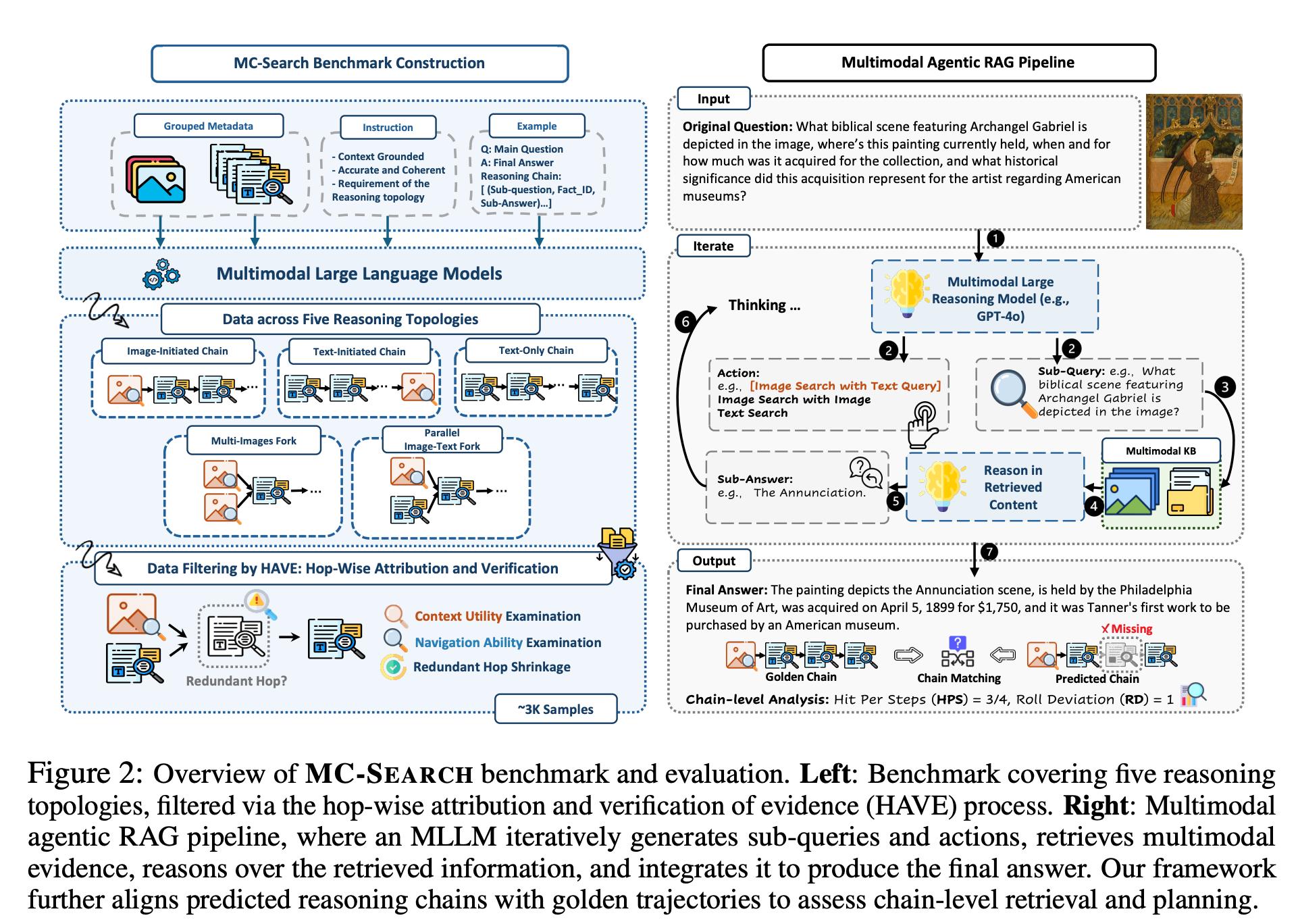
MC-SEARCH is the first comprehensive benchmark designed to evaluate Multimodal Agentic Retrieval-Augmented Generation (MM-RAG). Unlike traditional RAG, MC-SEARCH focuses on structured long reasoning chains where agents must navigate through vast knowledge bases (389K images and 784K documents) to solve complex queries.
Each instance in MC-SEARCH provides step-wise sub-questions, explicit retrieval modality annotations (image vs. text), and intermediate reasoning states, allowing for a fine-grained analysis of how agents plan and execute multimodal search.

We introduce five representative reasoning topologies that mirror real-world search patterns. We evaluate models not just on the final answer, but on their Hit-per-Step (HPS), Rollout Deviation (RD), and Planning Accuracy to pinpoint where agentic reasoning breaks down.
Our evaluation of state-of-the-art MLLMs (Multimodal Large Language Models) reveals critical bottlenecks in current agentic search capabilities:
💡 Compounding Errors: Retrieval fidelity drops significantly as reasoning depth exceeds 3 hops.
💡 Modality Gap: Current models struggle with maintaining consistency when switching between image and text retrieval.
💡 Process Supervision: Explicit reasoning alignment (like our SEARCH-ALIGN) substantially boosts retrieval success rates.